
How Amazon Expanded Rufus through Multi-Node Inference with AWS Trainium Chips and vLLM
At Amazon, our team develops Rufus, a generative AI-powered shopping assistant that caters to millions of customers at a vast scale. However, the deployment of Rufus at such scale comes with considerable challenges that need careful management. Rufus operates on a custom large language model (LLM). As the model’s complexity increased, we emphasized creating scalable multi-node inference capabilities that ensure high-quality interactions while also achieving low latency and cost-effectiveness.
In this article, we detail how we created a multi-node inference solution using Amazon Trainium and vLLM, an open-source library for efficient, high-throughput serving of LLMs. We also explain how we constructed a management layer on top of Amazon Elastic Container Service (Amazon ECS) to deploy models across numerous nodes, enhancing reliable and scalable deployments.
Challenges with multi-node inference
As our Rufus model expanded, we required multiple accelerator instances because no single instance possessed sufficient memory for the entire model. We first had to engineer the model to be distributed across several accelerators. Techniques like tensor parallelism enabled this, which also affects various metrics such as time to first token. At larger scales, one node’s accelerators may fall short, necessitating multiple hosts. Consequently, we had to manage the distribution of our model and its shards across these hosts (and their respective accelerators). We identified two main areas to address:
- Model performance – Optimize compute and memory resource utilization across multiple nodes to handle high-throughput models while ensuring low latency. This involves developing effective parallelism strategies and model weight-sharding methods to partition computation and memory usage within and across nodes, along with efficient batching that enhances hardware resource utilization amidst varying request patterns.
- Multi-node inference infrastructure – Design a containerized abstraction representing a single model running across multiple nodes. This infrastructure must enable quick inter-node communication, maintain consistency among distributed components, and allow for deployment and scaling as a unified deployable unit. Additionally, it should facilitate continuous integration for rapid iterations and safe, reliable rollouts in production settings.
Solution overview
Considering these requirements, we developed a multi-node inference solution aimed at overcoming the scalability, performance, and reliability challenges inherent in serving LLMs at production scale utilizing tens of thousands of TRN1 instances.
We created a leader/follower multi-node inference architecture within vLLM. In this setup, the leader node handles request scheduling, batching, and orchestration using vLLM, while follower nodes perform distributed model computations. Both leader and follower nodes utilize the same NeuronWorker implementation in vLLM, providing a uniform model execution pathway via seamless integration with the AWS Neuron SDK.
To effectively split the model across multiple instances and accelerators, we employed hybrid parallelism strategies supported by the Neuron SDK. Techniques like tensor parallelism and data parallelism are selectively utilized to optimize cross-node compute and memory bandwidth utilization, significantly boosting overall throughput.
Understanding the connectivity of the nodes is also crucial to avoid latency issues. We leveraged network topology-aware node placement. Optimized placements facilitate low-latency, high-bandwidth communication across nodes using Elastic Fabric Adapter (EFA), which minimizes communication overhead and enhances the efficiency of collective operations.
Finally, to manage models across multiple nodes, we developed a multi-node inference unit abstraction layer on Amazon ECS. This layer enables the deployment and scaling of multiple nodes as a cohesive unit, ensuring robust and reliable large-scale production deployments.
By integrating a leader/follower orchestration model, hybrid parallelism strategies, and a multi-node inference unit abstraction layer built on Amazon ECS, our architecture deploys a single model replica seamlessly across multiple nodes to support extensive production deployments. In the subsequent sections, we delve into the architecture and key components of the solution in greater detail.
Inference engine design
We created an architecture on Amazon ECS using TRN1 instances that enables scaling inference beyond a single node, effectively utilizing distributed hardware resources, while maintaining seamless integration with NVIDIA Triton Inference Server, vLLM, and the Neuron SDK.
Although the diagram below illustrates a two-node configuration (leader and follower) for clarity, the architecture is designed to be scalable to accommodate additional follower nodes as required.
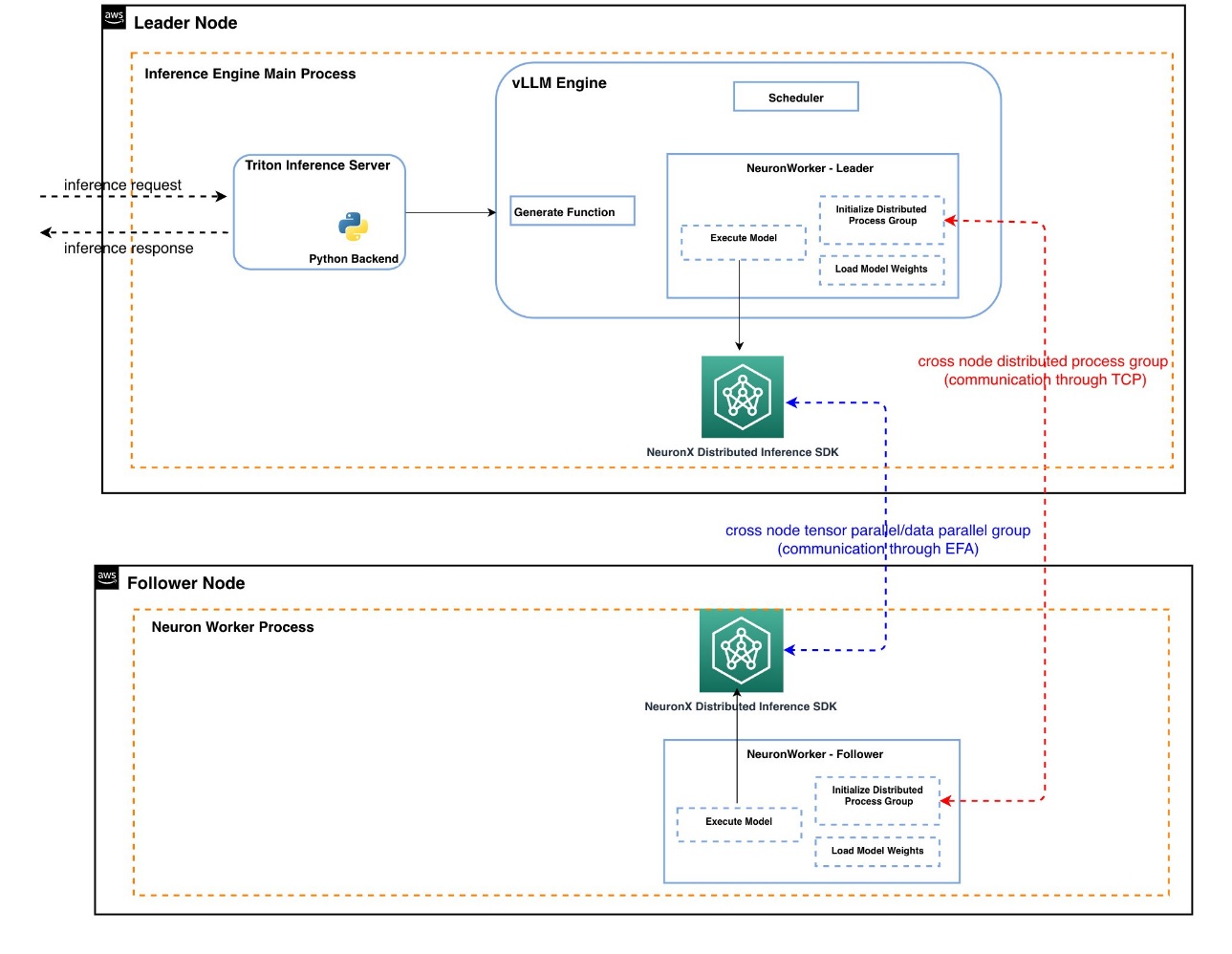
In this architecture, the leader node operates the Triton Inference Server and vLLM engine, serving as the main orchestration unit for inference. By integrating with vLLM, we implement continuous batching—a technique designed for LLM inference that enhances throughput and accelerator utilization by dynamically scheduling and processing inference requests at the token level. The vLLM scheduler manages batching in relation to the global batch size. Operative in a single-node context, it lacks awareness of multi-node model execution. Once requests are scheduled, they are sent to the NeuronWorker component in vLLM, which takes care of broadcasting model inputs and executing the model through its integration with the Neuron SDK.
The follower node functions as an independent process and acts as a wrapper around the vLLM NeuronWorker component. It continuously listens for model inputs broadcast by the leader node and executes the model using the Neuron runtime in sync with the leader node.
For effective communication between nodes, two mechanisms are necessary:
- Cross-node model input broadcasting on CPU – Model inputs are sent from the leader node to follower nodes utilizing the torch.distributed communication library with the Gloo backend. A distributed process group is established during NeuronWorker initialization on both leader and follower nodes. This broadcast takes place on CPU over standard TCP connections, enabling follower nodes to access the complete set of model inputs required for execution.
- Cross-node collectives communication on Trainium chips – During model execution, cross-node collective operations (like all gather or all reduce) are managed by the Neuron Distributed Inference (NxDI) library, employing EFA for efficient high-bandwidth, low-latency communication between nodes.
Model parallelism strategies
We implemented hybrid model parallelism strategies through collaboration with the Neuron SDK to enhance cross-node memory bandwidth utilization (MBU) and model FLOPs utilization (MFU), all while alleviating memory pressure on individual nodes. For instance, during the context encoding (prefill) phase, we leverage context parallelism by splitting inputs along the sequence dimension, thereby enabling parallel calculations of attention layers across nodes. In the decoding phase, we employ data parallelism by dividing the input along the batch dimension, so that each node can serve a subset of batch requests independently.
Multi-node inference infrastructure
Additionally, we conceptualized a distributed LLM inference abstraction: the multi-node inference unit, shown in the following diagram. This abstraction functions as a deployment unit for the inference service, enabling consistent and reliable rolling updates on a cell-by-cell basis across the production fleet. This guarantees that only a minimal number of nodes are taken offline during upgrades, preventing widespread service disruption. Both the leader and follower nodes from earlier discussions are fully containerized, allowing each node to be managed and updated independently while maintaining uniform execution environments throughout the fleet. Such consistency is vital for reliability, as both leader and follower nodes must operate with identical software stacks—including Neuron SDKs, Neuron drivers, EFA software, and other runtime dependencies—to ensure accurate and dependable multi-node inference execution. The inference containers are deployed via Amazon ECS.
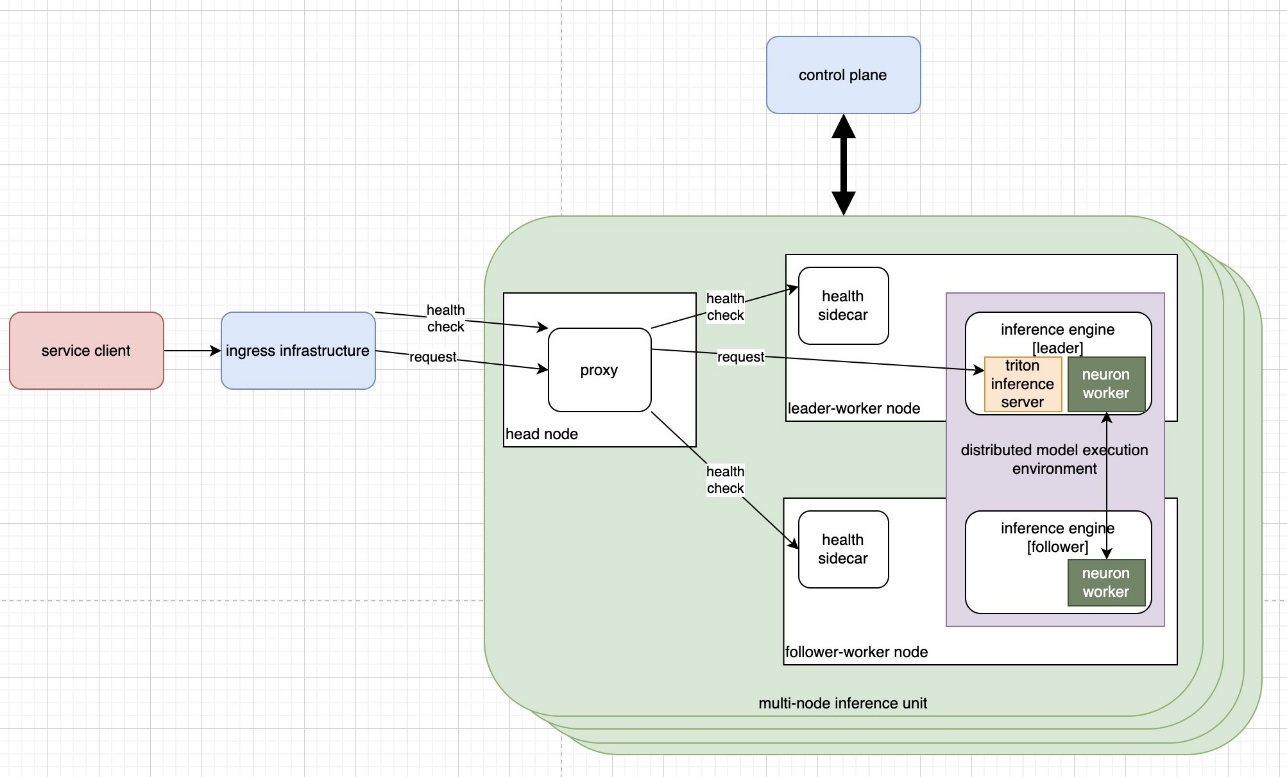
A critical element for achieving high-performance distributed LLM inference is minimizing latency during cross-node collective operations, which rely on Remote Direct Memory Access (RDMA). To facilitate this, optimized node placement is crucial: the deployment management system should construct a cell by pairing nodes based on their physical proximity. With this optimized arrangement, cross-node operations can take advantage of the high-bandwidth, low-latency EFA network available to instances. The deployment management system gathers the necessary information using the Amazon EC2 DescribeInstanceTopology API to optimally pair nodes according to their underlying network topology.
To ensure high availability for customers (ensuring Rufus is consistently online and ready to respond), we established a proxy layer between the system’s ingress or load-balancing layer and the multi-node inference unit. This proxy layer is responsible for continuously monitoring the health of all worker nodes. Swiftly identifying unhealthy nodes in a distributed inference environment is crucial for maintaining availability. This allows the system to immediately reroute traffic away from compromised nodes and activate automated recovery processes to restore stability in service.
The proxy also tracks real-time load across each multi-node inference unit and relays this data to the ingress layer, facilitating detailed, system-wide load visibility. This enhanced visibility aids the load balancer in making optimized routing decisions that maximize per-cell performance and overall efficiency in the system.
Conclusion
As Rufus evolves to become more capable, we are also focused on building systems that can support our model. Through this multi-node inference solution, we successfully deployed a significantly larger model across tens of thousands of AWS Trainium chips to our Rufus customers, especially during Prime Day traffic. This enhancement in model capacity has resulted in new shopping experiences and a marked improvement in user engagement. This accomplishment signifies a major milestone in advancing large-scale AI infrastructure for Amazon, offering a highly available, high-throughput multi-node LLM inference solution that meets industry standards.
Using AWS Trainium alongside solutions like NVIDIA Triton and vLLM can empower you to manage extensive inference workloads cost-effectively. We encourage you to explore these solutions to host substantial models tailored to your needs.
About the authors
 James Park is an ML Specialist Solutions Architect at Amazon Web Services, collaborating with Amazon.com to design, build, and deploy technology solutions on AWS, with a particular focus on AI and machine learning. In his free time, he enjoys exploring new cultures, seeking new experiences, and keeping abreast of the latest technological trends.
James Park is an ML Specialist Solutions Architect at Amazon Web Services, collaborating with Amazon.com to design, build, and deploy technology solutions on AWS, with a particular focus on AI and machine learning. In his free time, he enjoys exploring new cultures, seeking new experiences, and keeping abreast of the latest technological trends.
 Faqin Zhong is a Software Engineer at Amazon Stores Foundational AI, specializing in LLM inference infrastructure and optimization. Passionate about generative AI technology, Faqin works alongside leading teams to drive innovation, making LLMs more accessible and impactful, thereby enhancing customer experiences across various applications. In her downtime, she enjoys cardio exercising and baking with her son.
Faqin Zhong is a Software Engineer at Amazon Stores Foundational AI, specializing in LLM inference infrastructure and optimization. Passionate about generative AI technology, Faqin works alongside leading teams to drive innovation, making LLMs more accessible and impactful, thereby enhancing customer experiences across various applications. In her downtime, she enjoys cardio exercising and baking with her son.
 Charlie Taylor is a Senior Software Engineer within Amazon Stores Foundational AI, focusing on the development of distributed systems for high-performance LLM inference. He constructs inference systems and infrastructure to facilitate quicker responses from larger, more capable models. Outside work, he enjoys reading and surfing.
Charlie Taylor is a Senior Software Engineer within Amazon Stores Foundational AI, focusing on the development of distributed systems for high-performance LLM inference. He constructs inference systems and infrastructure to facilitate quicker responses from larger, more capable models. Outside work, he enjoys reading and surfing.
 Yang Zhou is a Software Engineer dedicated to building and optimizing machine learning systems, with recent efforts focused on enhancing generative AI inference’s performance and cost-efficiency. Outside of work, he enjoys traveling and has recently developed a passion for long-distance running.
Yang Zhou is a Software Engineer dedicated to building and optimizing machine learning systems, with recent efforts focused on enhancing generative AI inference’s performance and cost-efficiency. Outside of work, he enjoys traveling and has recently developed a passion for long-distance running.
 Nicolas Trown is a Principal Engineer at Amazon Stores Foundational AI, focusing on applying his systems expertise across Rufus to assist the Rufus Inference team and ensure efficient utilization across the Rufus experience. Outside of work, he enjoys family outings and exploring nearby beaches and wine regions.
Nicolas Trown is a Principal Engineer at Amazon Stores Foundational AI, focusing on applying his systems expertise across Rufus to assist the Rufus Inference team and ensure efficient utilization across the Rufus experience. Outside of work, he enjoys family outings and exploring nearby beaches and wine regions.
 Michael Frankovich is a Principal Software Engineer at Amazon Core Search, where he supports the ongoing development of their cellular deployment management system used to host Rufus, among other search applications. In his spare time, he enjoys playing board games and caring for his chickens.
Michael Frankovich is a Principal Software Engineer at Amazon Core Search, where he supports the ongoing development of their cellular deployment management system used to host Rufus, among other search applications. In his spare time, he enjoys playing board games and caring for his chickens.
 Adam (Hongshen) Zhao is a Software Development Manager at Amazon Stores Foundational AI, currently leading the Rufus Inference team to create generative AI inference optimization solutions and scalable inference systems for quick and low-cost inference. Outside of work, he loves to travel with his wife and express himself through art.
Adam (Hongshen) Zhao is a Software Development Manager at Amazon Stores Foundational AI, currently leading the Rufus Inference team to create generative AI inference optimization solutions and scalable inference systems for quick and low-cost inference. Outside of work, he loves to travel with his wife and express himself through art.
 Bing Yin is a Director of Science at Amazon Stores Foundational AI, spearheading the development of LLMs tailored for shopping use cases and optimized for inference at Amazon scale. Outside of work, he participates in marathon races.
Bing Yin is a Director of Science at Amazon Stores Foundational AI, spearheading the development of LLMs tailored for shopping use cases and optimized for inference at Amazon scale. Outside of work, he participates in marathon races.
 Parthasarathy Govindarajen is the Director of Software Development at Amazon Stores Foundational AI. He leads teams that create sophisticated infrastructure for large language models, focusing on both training and inference at scale. When not at work, he enjoys playing cricket and discovering new places with his family.
Parthasarathy Govindarajen is the Director of Software Development at Amazon Stores Foundational AI. He leads teams that create sophisticated infrastructure for large language models, focusing on both training and inference at scale. When not at work, he enjoys playing cricket and discovering new places with his family.