
Upgrade AI agents with predictive machine learning models using Amazon SageMaker and the Model Context Protocol (MCP).
Machine learning (ML) has transitioned from a phase of experimentation to a vital element of business functions. Companies are now utilizing ML models for accurate sales predictions, customer segmentation, and churn forecasting. While conventional ML is still pivotal in refining business processes, generative AI has emerged as a transformative force, offering potent and accessible tools that redefine customer interactions.
Although generative AI is gaining prominence, traditional ML solutions are crucial for particular predictive tasks. Sales forecasting relies heavily on historical data and trend analysis, effectively managed by well-established ML algorithms such as random forests, gradient boosting machines (including XGBoost), autoregressive integrated moving average (ARIMA) models, long short-term memory (LSTM) networks, and linear regression methods. In applications like customer segmentation and churn prediction, traditional ML models like K-means and hierarchical clustering excel. While generative AI excels in creative tasks such as generating content, product design, and personalized customer engagement, conventional ML models remain unmatched in data-centric predictions. By integrating both approaches, organizations can achieve optimal outcomes, delivering precise predictions while ensuring cost-effectiveness.
This post highlights how customers can enhance AI agents’ functionalities by incorporating predictive ML models and Model Context Protocol (MCP)—an open protocol that standardizes contextual information provided to large language models (LLMs)—using Amazon SageMaker AI. We illustrate a detailed workflow that empowers AI agents to make data-informed business decisions by leveraging ML models hosted on SageMaker. Utilizing the Strands Agents SDK—an open-source SDK that enables a model-driven strategy for building and deploying AI agents with minimal code—and versatile integration methods, including direct endpoint access and MCP, we demonstrate how to create intelligent, scalable AI applications that merge conversational AI with predictive analytics.
Solution Overview
This solution enriches AI agents by connecting ML models deployed on Amazon SageMaker AI endpoints to enable data-driven business decisions via ML predictions. An AI agent operates as an LLM-powered application, using an LLM as its central “brain” to autonomously observe environments, plan actions, and accomplish tasks with minimal human oversight. It incorporates reasoning, memory, and tool usage to tackle complex, multi-step issues by dynamically formulating and revising plans, interacting with external systems, and learning from previous experiences to enhance outcomes over time. This capability allows AI agents to transcend simple text generation, functioning as autonomous entities capable of decision-making and goal-oriented actions in various real-world and enterprise contexts. For this solution, we develop the AI agent utilizing the Strands Agents SDK, facilitating quick development from basic assistants to intricate workflows. The predictive ML models are hosted on Amazon SageMaker AI and serve as resources for the AI agent, utilizing two methods: agents can directly call SageMaker endpoints for immediate access to model inference capabilities or employ the MCP protocol for interaction between AI agents and the ML models. Both options are valid: direct invocation does not necessitate additional infrastructure as it embeds tool calling directly in the agent’s code, whereas MCP promotes dynamic tool discovery and separates agent and tool execution through an additional component, the MCP server. For secure, scalable implementation of the tool calling logic, we recommend the MCP approach. Although MCP is preferred, we also discuss and implement direct endpoint access, allowing readers to select their preferred method.
Amazon SageMaker AI offers two approaches to host multiple models behind a single endpoint: inference components and multi-model endpoints. This unified hosting method facilitates the efficient deployment of various models within a single environment, optimizing computation resources and reducing response times for predictions. For demonstration, this post deploys a single model on one endpoint. To learn more about inference components, consult the Amazon SageMaker AI documentation on Shared resource utilization with multiple models. For details about multi-model endpoints, refer to the Amazon SageMaker AI documentation on Multi-model endpoints.
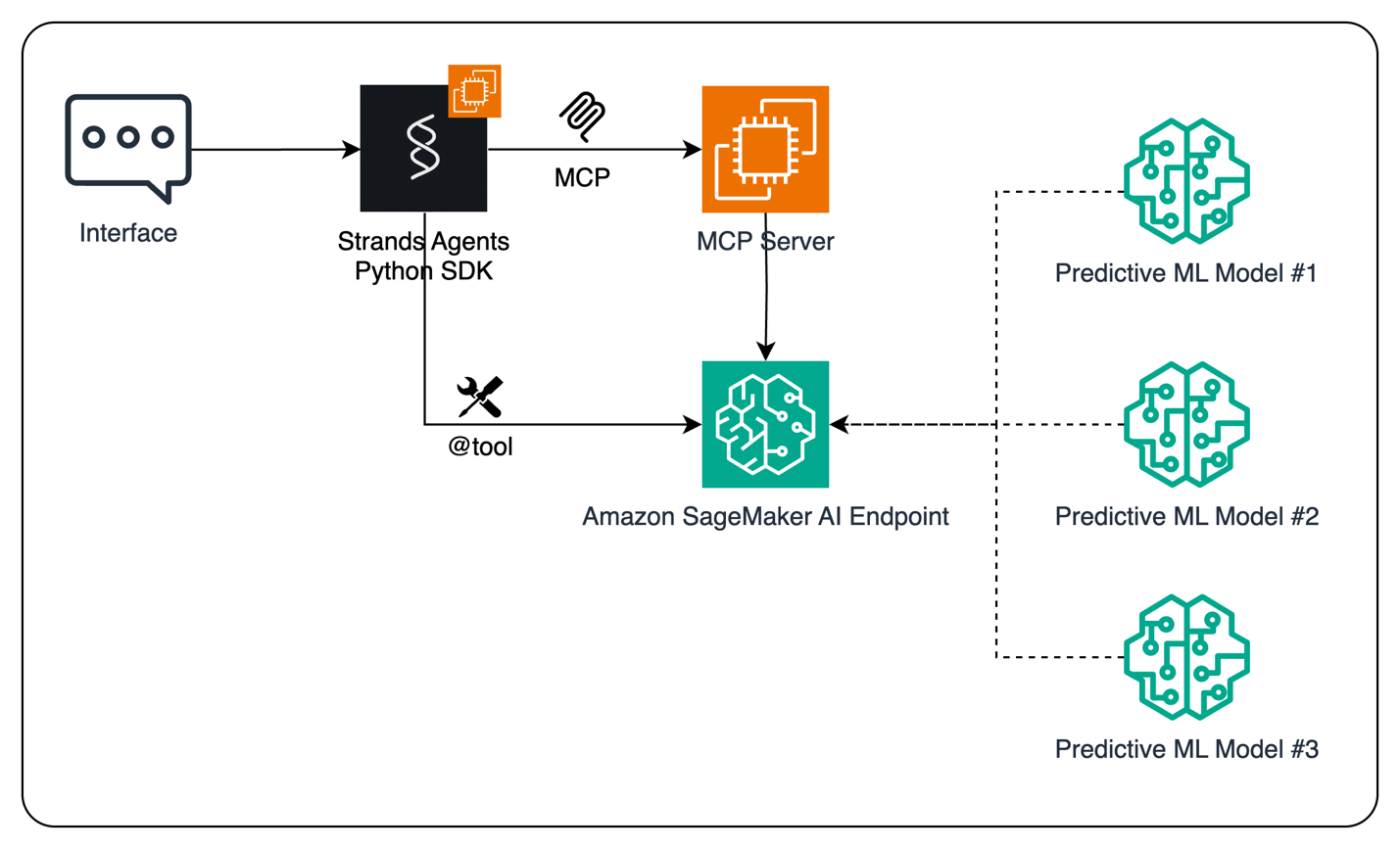
Architecture
This post delineates a workflow designed to empower AI agents in making data-driven business decisions through invoking predictive ML models with Amazon SageMaker AI. The process initiates with a user interacting through an interface, such as a chat-based assistant or application. This input is processed by an AI agent developed using the open-source Strands Agents SDK. Strands Agents adopts a model-driven philosophy, allowing developers to define agents with just a prompt and a tool list, thereby facilitating swift development from basic assistants to sophisticated autonomous workflows.
When prompted with a request necessitating a prediction (for instance, “what will sales be for H2 2025?”), the LLM governing the agent resolves to interact with the Amazon SageMaker AI endpoint housing the ML model. This interaction can occur through two pathways: directly using the endpoint as a custom tool in the Strands Agents Python SDK or by invoking the tool via MCP. With MCP, the client application can discover the tools made available by the MCP server, gather the necessary parameters, and format the request for the Amazon SageMaker inference endpoint. Conversely, agents may directly call SageMaker endpoints using tool annotations (like @tool), circumventing the MCP server for immediate model inference access.
Subsequently, the prediction generated by the SageMaker-hosted model is delivered back through the agent and ultimately to the user interface, allowing real-time, intelligent responses.
The diagram below illustrates this process. The full code for this solution is available on GitHub.
Prerequisites
To get started with this solution, ensure the following requirements are met:
Solution Implementation
This solution entails a full workflow demonstrating the utilization of ML models hosted on Amazon SageMaker AI as specialized tools for AI agents. This enables agents to leverage ML functionalities for enhanced decision-making without deep expertise in ML. Here, we take the role of a data scientist tasked with creating an agent to predict demand for a single product. To accomplish this, we train a time-series forecasting model, deploy it, and make it available to an AI agent.
The initial phase focuses on training a model using Amazon SageMaker AI. This begins with preparing training data by generating synthetic time series data that includes trend, seasonality, and noise components to realistically simulate demand. Following data preparation, feature engineering is employed to extract pertinent features from the time series data, incorporating temporal aspects such as the day of the week, month, and quarter to effectively capture seasonality. In our case, we train an XGBoost model using the XGBoost container provided as a first-party container in Amazon SageMaker AI to produce a regression model capable of predicting future demand based on historical patterns. While XGBoost serves as our example because of its widespread applicability, you can use any preferred container and model, depending on your specific problem. We won’t delve into a complete step-by-step example of training a model with XGBoost in this post; for further information, please refer to the documentation on Using XGBoost with the SageMaker Python SDK. Use the following code:
Next, the trained model is packaged and deployed to a SageMaker AI endpoint, making it available for real-time inference via API calls:
Once the model is deployed and ready for inference, you will need to learn how to invoke the endpoint. To call the endpoint, you can create a function similar to this:
Note that the function invoke_endpoint() has been designed with a thorough docstring. This is essential for ensuring its usability as a tool by LLMs since the description guides them in selecting the appropriate tool for the task. You can convert this function into a Strands Agents tool by utilizing the @tool decorator:
To utilize this, provide it to a Strands agent:
As you execute this code, you can verify the agent’s output as it correctly identifies the necessity to invoke the tool and performs the function calling loop:
Once the agent receives the prediction result from the endpoint tool, it can use this information as input for further processes. For instance, the agent might create a plot based on these predictions and present it to the user in the conversational interface. It could also relay these values directly to business intelligence (BI) tools such as Amazon QuickSight or Tableau, or automatically update enterprise resource planning (ERP) or customer relationship management (CRM) systems such as SAP or Salesforce.
Connecting to the Endpoint through MCP
This pattern can be further developed by having an MCP server invoke the endpoint instead of the agent directly. This approach promotes a separation of agent and tool logic and enhances security, as the MCP server will possess the permission to invoke the endpoint. To implement this, establish an MCP server using the FastMCP framework, which wraps the SageMaker endpoint and presents it as a tool with a clearly defined interface. You’ll need to specify a tool schema that accurately describes the input parameters and return values for the tool, facilitating straightforward comprehension and usage by AI agents. Creating an appropriate docstring when defining the function achieves this goal. Moreover, the server must be configured for secure authentication, enabling it to access the SageMaker endpoint with AWS credentials or AWS roles. In this example, we run the server on the same compute as the agent and utilize stdio as the communication protocol. For production applications, we advise deploying the MCP server on a separate AWS compute instance and using HTTPS-based transport protocols (for instance, Streamable HTTP). For insights on serverless MCP server deployment, please refer to this official AWS GitHub repository. Below is an example MCP server:
Finally, connect the ML model to the agent framework. This initiation involves configuring Strands Agents to communicate with the MCP server and incorporate the ML model as a tool. A comprehensive workflow must be established to identify when and how the agent should utilize the ML model to augment its capabilities. The implementation includes programming decision-making logic enabling the agent to make informed choices based on the predictions obtained from the ML model. This phase concludes with testing and evaluation, verifying the end-to-end workflow as the agent generates predictions for test scenarios and takes appropriate actions based on those predictions.
Clean Up
Once you finish experimenting with the Strands Agents Python SDK and models on Amazon SageMaker AI, ensure you delete the endpoint you created to avoid incurring unnecessary charges. You can accomplish this through the AWS Management Console, the SageMaker Python SDK, or the AWS SDK for Python (boto3):
Conclusion
This post illustrated how to enhance AI agents’ functionalities by integrating predictive ML models via Amazon SageMaker AI and MCP. By leveraging the open-source Strands Agents SDK and the diverse deployment options within SageMaker AI, developers can create sophisticated AI applications that merge conversational AI with robust predictive analytics. The presented solution provides two integration paths: direct endpoint access through tool annotations and MCP-based integration, granting developers flexibility in choosing the best method for their specific use cases. Whether you’re developing customer service chat assistants needing predictive capabilities or designing intricate autonomous workflows, this architecture delivers a secure, scalable, and modular foundation for your AI applications. As organizations increasingly strive to enhance their AI agents’ intelligence and data-driven capabilities, the collaboration of Amazon SageMaker AI, MCP, and the Strands Agents SDK offers a dynamic solution for constructing next-generation AI-driven applications.
For readers less familiar with linking MCP servers to workloads operating on Amazon SageMaker AI, we recommend visiting Extend large language models powered by Amazon SageMaker AI using Model Context Protocol in the AWS Artificial Intelligence Blog, which outlines the flow and necessary steps for creating agentic AI solutions with Amazon SageMaker AI.
To delve deeper into AWS’s commitment to MCP standards, we suggest reading Open Protocols for Agent Interoperability Part 1: Inter-Agent Communication on MCP in the AWS Open Source Blog, announcing AWS’s inclusion in the steering committee for MCP, enabling developers to create groundbreaking agentic applications without being confined to a single standard. For more information on integrating MCP with other AWS technologies like Amazon Bedrock Agents, check out Harness the power of MCP servers with Amazon Bedrock Agents in the AWS Artificial Intelligence Blog. Lastly, a secure and scalable method to deploy MCP servers on AWS is available in the AWS Solutions Library at Guidance for Deploying Model Context Protocol Servers on AWS.
About the Authors
 Saptarshi Banerjee , a Senior Solutions Architect at AWS, partners closely with AWS Partners to design robust solutions. With a focus on generative AI, AI/ML, serverless architecture, and next-gen developer tools, Saptarshi aims to elevate performance, innovation, scalability, and cost-effectiveness for AWS Partners in the cloud space.
Saptarshi Banerjee , a Senior Solutions Architect at AWS, partners closely with AWS Partners to design robust solutions. With a focus on generative AI, AI/ML, serverless architecture, and next-gen developer tools, Saptarshi aims to elevate performance, innovation, scalability, and cost-effectiveness for AWS Partners in the cloud space.
 Davide Gallitelli , a Senior Worldwide Specialist Solutions Architect for Generative AI at AWS, empowers enterprises worldwide to harness AI’s transformative potential. Based in Europe with a global focus, Davide collaborates with various organizations to architect tailored AI agents that address complex business needs utilizing the AWS ML stack. He is particularly engaged in democratizing AI technology, enabling teams to build practical, scalable solutions driving organizational transformation.
Davide Gallitelli , a Senior Worldwide Specialist Solutions Architect for Generative AI at AWS, empowers enterprises worldwide to harness AI’s transformative potential. Based in Europe with a global focus, Davide collaborates with various organizations to architect tailored AI agents that address complex business needs utilizing the AWS ML stack. He is particularly engaged in democratizing AI technology, enabling teams to build practical, scalable solutions driving organizational transformation.